
In this multi-series blog, I am going to cover NoSQL, CosmosDB and DocumentDB from scratch to complete implementation. So, hop onboard and let’s get started!
NoSQL? Really?
There are a few basic things I learned at RDBMS (Relational Database Management) class 101 – Data should be normalized, not duplicated, consistent and, of course, related. So, when I first heard about No-SQL a few years ago, and how it promotes non-related, no-schema data, I thought to myself, why exactly would you do that?
Yes, for NoSQL! This is Why.
Real story. One day, I decided to organize my kid’s Toy room. I started cleaning Lego blocks; I bought a few Lego-like looking boxes and put each set into an individual box with its original manual (how fancy!). Some sets were too small and would leave a lot of space in the box, some were big and would not fit in the box. When my little boy started tinkering he wanted a piece from box #1, and then another piece from box #4, which meant he must now get all the boxes down, collect each piece to build his master Lego art and then after playtime put everything back in their respective boxes. This would kill the fun out of it, wouldn’t it now?

So I came up with a very “innovative” idea and dumped everything into a single box 🙂 Now, everything he needed was there is that one big bin, also there was no size restriction, all the blocks, big and small, fit in well together. There was no limit to his joy! Later I made similar bins for kitchen toys, dolls, cars, books, etc.
This story is analogous to NoSQL. Instead of structuring data into rigid shapes and then finding a perfect peg for that hole, we let the data to be fluid and self-contained. Fluid data is then put in containers where it can be found easily when asked for. Let’s now relate this to a more real-world professional example.
We created a Content Management E-commerce website for a Home Owners Association which allowed users to pay their assessments online. I am going to use this as problem definition and build some hypothetical scenarios. Suppose they want to open an online store and sell pool passes to tenants who have paid their assessment fees. To design this, we would create relational database tables to save pool pass information and provide an e-commerce shopping cart to complete orders. Our table will look something like this.
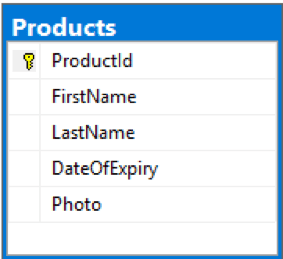
So far, so good. Later they want to sell summer camps online. This product is completely different than pool passes so the logical thing would be to add more columns to Product table which will stay blank is not applicable, or have some sort of an inheritance between Product as parent and children such as pool passes, Camps, etc. Let’s say we choose to have two separate tables for pool passes and camps. Camps will have different fields such as Start Date, End Date, Season, Teacher, etc.
Now, maybe they want to sell camp T-shirts, so we need another table with fields like size, color, etc. Tomorrow they might come up with other merchandise such as key fobs, so for every new product we either end up adding more columns specific to the product or adding more tables.
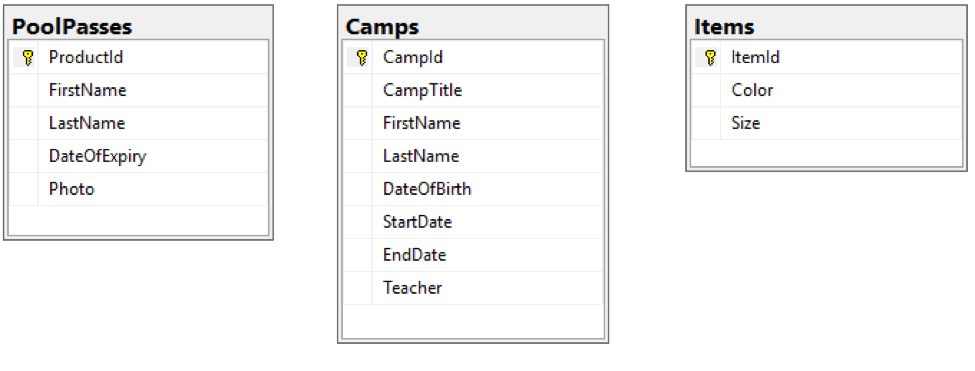
An alternative smarter way would be to maintain a list of attributes such that every product has a list of attributes. Now when we want to fetch a product then we need to join attributes table and flatten the data to display a single product.

Wouldn’t it be nice if we can keep our product entity as fluid as possible and fill in data as deemed required? This is where NoSQL fits well. NoSQL offers data storage in a schema-free format unlike SQL hence the word NoSQL.
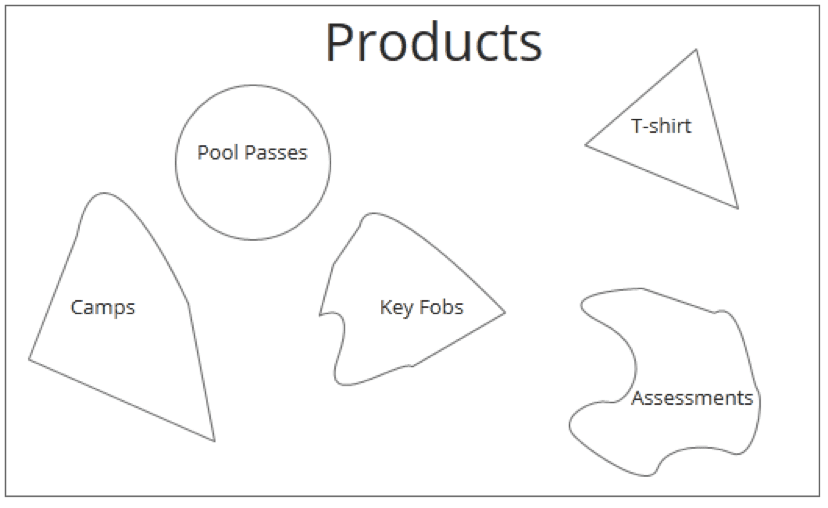
NoSQL representation of Products
How exactly is data stored in NoSQL? How to retrieve and create new data? These and more questions will be covered in my next blog where I am going to concentrate on Document DB (NoSQL by Microsoft). Stay tuned…





















